
Picture this: You open Databricks Marketplace, ready to pick a model for your new AI project. You're greeted with Meta Llama 3.3, OpenAI GPT OSS, Google Gemini, Qwen3-Next, and about ten other options staring back at you.
Which one do you choose?
If you're like most ML engineers I've talked to, you probably do one of three things:
Pick the one with the biggest parameter count (because bigger = better, right?)
Choose whatever's trending on tech Twitter this week
Spend three days testing everything and still feel uncertain
Here's what nobody tells you: the "best" model doesn't exist. What exists is the right model for your specific use case.
Last month, I watched a team deploy a 70B parameter model for a simple customer FAQ bot. Overkill? Absolutely. They switched to a lightweight 20B model and cut costs by 60% with zero drop in quality. On the flip side, I've seen teams try to squeeze complex reasoning tasks out of models that were never designed for it, then wonder why their accuracy tanked.
The Databricks Marketplace has evolved into a full AI ecosystem with foundation models, AI agents, MCP servers, and solution accelerators. It's genuinely powerful—but only if you know how to navigate it.
So let's skip the guesswork. Whether you're building a conversational agent, deploying a text generation system, or just trying to figure out which model won't blow your budget, this guide breaks down the exact criteria that actually matter.
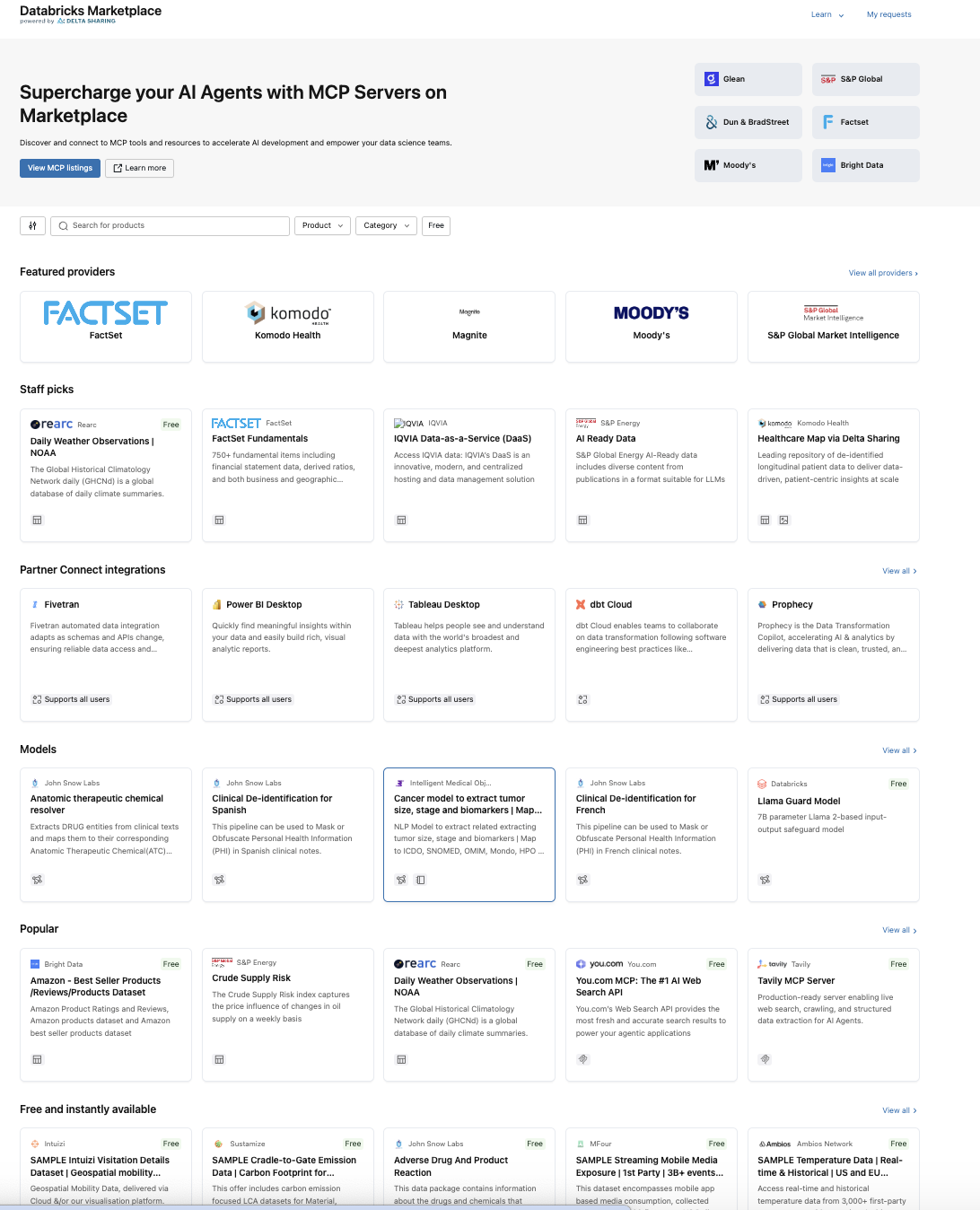
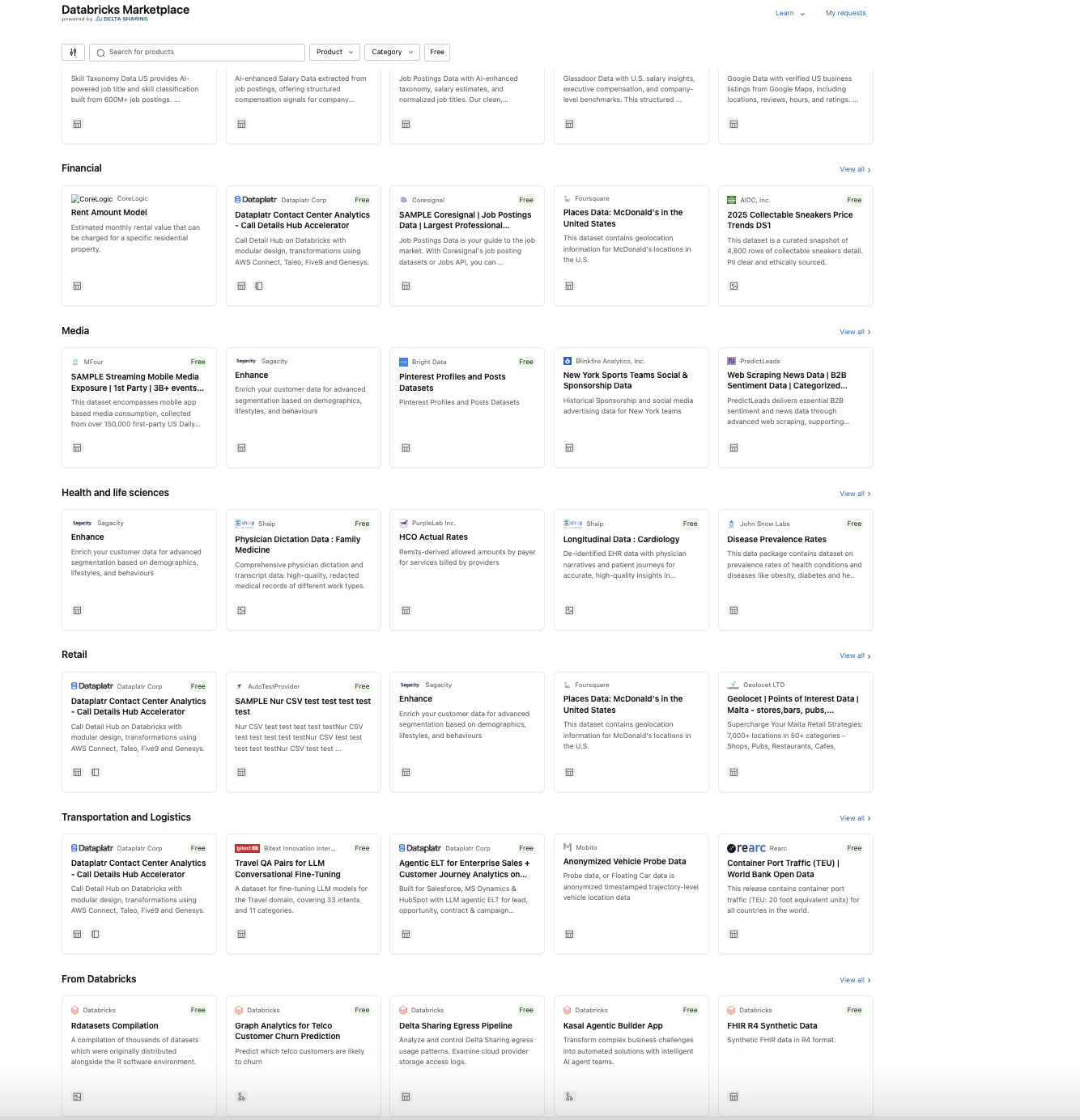
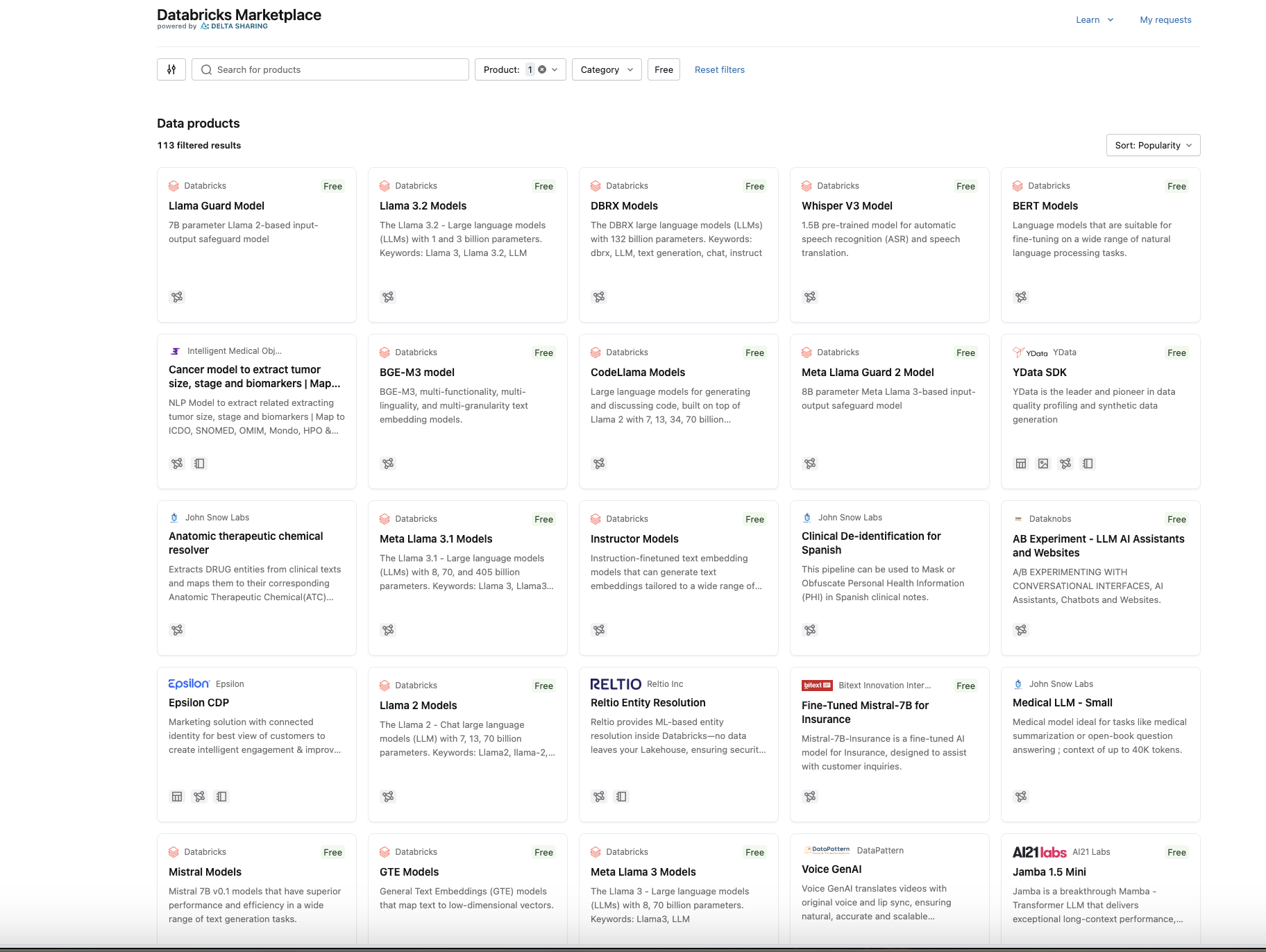
Databricks Marketplace isn't just about foundation models anymore. It now offers:
Foundation Models: Pre-trained LLMs like Meta Llama, OpenAI GPT, Google Gemini, and specialized models from Alibaba Cloud
AI Agents and MCP Servers: Tools that connect AI systems to external data sources and APIs
Solution Accelerators: Pre-built notebooks demonstrating specific use cases
Datasets: Both public and commercial data products
The marketplace supports models through different deployment options: pay-per-token endpoints for quick experimentation, provisioned throughput for production workloads, and external model integrations for third-party services.
Before we dive deep into selection criteria, here's a practical table to give you a starting point. Think of this as your "cheat sheet" for matching common use cases to appropriate models:
Use Case | Recommended Models | Why This Model? | Key Considerations |
Conversational AI Agents |
| Strong instruction-following, function calling support, maintains context across multi-turn conversations | Need function calling? Choose models with tool integration support |
Text Generation & Content Creation |
| Chain-of-thought reasoning, creative outputs, long-form coherence | Consider context window size (128K tokens) for longer documents |
Real-Time Copilots & Assistants |
| Lightweight, fast response times, cost-efficient for high throughput | Latency-sensitive? Prioritize Flash models |
Complex Reasoning & Analysis |
| Adjustable reasoning effort, step-by-step problem solving, mathematical accuracy | Best for tasks requiring transparent logic |
Multimodal Applications |
| Processes both text and images, unified understanding across modalities | Need vision? Only select models with image support |
Document Analysis & RAG |
| Ultra-long context windows (up to 128K), retrieval-augmented generation optimized | Match context length to your document size |
Batch Processing & Inference |
| Optimized for AI Functions, handles high-volume batch jobs efficiently | Volume matters—use AI Functions for scale |
Enterprise Compliance Workflows | Models with HIPAA support (Provisioned throughput mode) | Security certifications, data residency controls, fine-grained governance | Healthcare/Finance? Compliance is non-negotiable |
Prototyping & Experimentation | Any pay-per-token model | Low upfront cost, no infrastructure setup, easy to swap models | Start here, then optimize for production |
How to Use This Table:
Find your primary use case in the left column
Start with the recommended models
Read the "Why" to understand the match
Check "Key Considerations" for deal-breakers
Then dive into the detailed criteria below to refine your choice
Now let's break down exactly how to evaluate these models for your specific requirements.
Not all models are created equal. Start by identifying your primary use case:
For Conversational AI Agents: Look for models with strong instruction-following capabilities and function-calling support. Models like Meta Llama 3.3 70B Instruct and Qwen3-Next 80B excel at multi-step workflows and maintaining context across conversations. These models support tool integration, allowing your agent to query databases, execute code, or call external APIs.
For Text Generation and Content Creation: Models optimized for creativity and coherent long-form content work best here. OpenAI GPT OSS 120B brings chain-of-thought reasoning with adjustable effort levels, while Google's Gemini 2.5 Pro handles multimodal inputs and offers both quality and speed.
For Lightweight, Real-Time Applications: If you're building copilots or need rapid batch inference, consider lightweight models like OpenAI GPT OSS 20B or Gemini 2.5 Flash. These models balance performance with cost-efficiency, making them ideal for high-throughput scenarios.
The most powerful model isn't always the right choice. Consider these factors:
Token Pricing: Pay-per-token endpoints charge based on usage, making them perfect for experimentation. For instance, you might start with a larger model during development, then optimize down to a smaller model for production after establishing performance baselines.
Provisioned Throughput: Production workloads requiring consistent performance need dedicated capacity. This option provides performance guarantees and supports fine-tuned models with HIPAA compliance for sensitive applications.
Context Window Requirements: Models like Qwen3-Next 80B offer ultra-long context windows (128K tokens), essential for analyzing lengthy documents or maintaining extensive conversation history. If your use case doesn't require this, a model with a shorter context window might save costs.
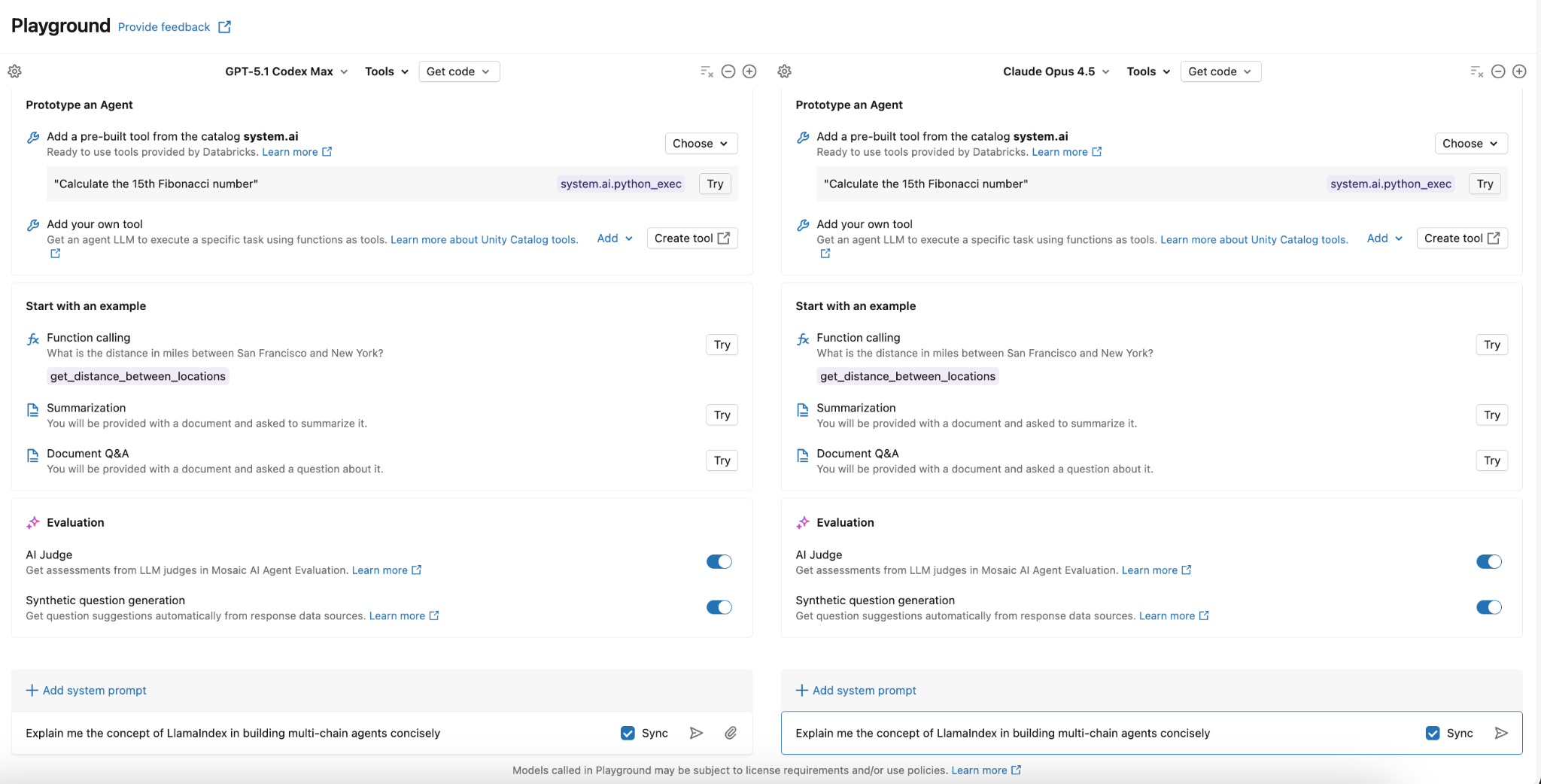
Databricks AI Playground offers a no-code environment to compare models directly. Here's how to use it effectively:
Run Identical Prompts: Test 2-3 models with the same prompts to compare response quality, tone, and accuracy
Enable Tools: For agent use cases, add Unity Catalog functions or vector search indices to see how models handle tool integration
Iterate on Prompts: Different models respond differently to prompt engineering—what works for one might fail for another
The synchronized comparison feature lets you evaluate responses side-by-side, making quality differences immediately apparent.
Some use cases demand specialized capabilities:
For Multimodal Applications: Models like Gemini 3 12B support both text and image inputs, essential for applications that need to process screenshots, diagrams, or product photos alongside text.
For Reasoning Tasks: Models with chain-of-thought capabilities (like GPT OSS 120B) excel at complex problem-solving, mathematical calculations, and logical inference. These models break down problems step-by-step, making their reasoning transparent.
For Enterprise Integration: If you're working within strict data governance frameworks, prioritize models that support Delta Sharing, Unity Catalog integration, and compliance certifications. Databricks-hosted models with provisioned throughput offer HIPAA compliance for healthcare applications.
Here's a game-changer: instead of manually testing dozens of models, use Agent Bricks to automate the selection process. This feature:
Auto-generates Evaluation Benchmarks: Creates domain-specific tests based on your data and task description
Optimizes Cost vs. Quality: Automatically tests different models, prompts, and configurations to find the sweet spot
Provides Continuous Improvement: Incorporates feedback to refine model selection over time
Agent Bricks is particularly valuable when you're not sure which model to start with—it eliminates the guesswork by testing multiple options programmatically.
Let's walk through a real-world example. Suppose you're building a customer support agent that needs to:
Answer questions using internal documentation
Escalate complex issues to human agents
Track conversation context across sessions
Step 1: Define Requirements
Need: Strong instruction-following, function calling, RAG support
Volume: 10,000 queries/day
Budget: Moderate
Latency: < 2 seconds
Step 2: Shortlist Models Based on requirements:
Meta Llama 3.3 70B Instruct (balanced performance)
Qwen3-Next 80B (excellent at multi-step workflows)
Gemini 2.5 Flash (cost-effective, fast)
Step 3: Test in AI Playground Run 20-30 representative queries through each model, focusing on:
Accuracy of document retrieval
Quality of generated responses
Ability to recognize escalation triggers
Step 4: Optimize with Agent Bricks Let Agent Bricks fine-tune the winning model with your actual data, automatically handling prompt optimization and evaluation.
Step 5: Deploy with Monitoring Start with provisioned throughput for consistency, implement logging to track performance, and gather user feedback for continuous refinement.
Choosing Based on Size Alone: A 70B parameter model isn't automatically better than a 20B model for your specific task. Smaller, specialized models often outperform larger general-purpose ones.
Ignoring Model Updates: Databricks frequently adds new models and retires older ones. For example, Meta Llama 3.3 70B recently replaced Llama 3.1 70B. Stay informed about deprecations and recommended migrations.
Skipping the Playground: It's tempting to deploy based on benchmarks alone, but 5-10 minutes in AI Playground can save hours of production debugging.
Overlooking Licensing: Each model has its own license and acceptable use policy. Review these carefully, especially for commercial applications.
When selecting models from Databricks Marketplace, remember:
Match the task first: Agent work, text generation, and batch inference each have ideal model profiles
Balance cost and performance: The most expensive model isn't always the most effective
Test before deploying: AI Playground makes side-by-side comparison effortless
Leverage automation: Agent Bricks handles optimization better than manual tuning
Stay informed: Model availability changes—subscribe to Databricks updates
The right model depends on your specific combination of requirements, budget, and technical constraints. Start broad, test thoroughly, and let your actual data guide the final decision. With Databricks Marketplace offering everything from lightweight copilot models to heavyweight reasoning engines, there's a perfect fit for virtually every AI use case—you just need to know where to look.
Ready to explore models in Databricks Marketplace? Start with AI Playground to compare models risk-free, or dive into Agent Bricks for automated optimization tailored to your specific needs.
Spark optimization isn't always complex; some tweaks have a huge impact. Inferring schemas forces Spark to scan your data twice, slowing ingestion and inflating cost. Explicit schemas avoid the extra pass and make pipelines faster and cheaper.

Cricket is no longer just a game of "gut feelings." This blog uncovers how hidden metrics like Expected Wickets and "Ghost" simulations are winning matches before the first ball. Dive into the high-stakes world where data science meets the 22 yards to redefine the sport.
I tested a simple hypothesis about image similarity - and watched it fail spectacularly when my algorithm said a "3" looks more like an "8" than another "3". The investigation revealed why pixel-by-pixel comparison is too brittle and what humans do effortlessly that machines must learn explicitly.
Passed the Databricks Gen AI Associate Certification with 56 questions in 90 minutes! Here's my honest experience, preparation strategy, time management tricks, and the exact resources that helped me succeed. Real insights for aspiring certificants.

A practical walkthrough of how I reduced heavy batch workloads using Change Data Feed (CDF) in Databricks. This blog shows how CDF helps process only updated records, cutting compute costs and boosting pipeline efficiency.

I dropped a table in Snowflake, then queried to verify it was gone. The system said it doesn't exist, but also showed it consuming 3.57 MB. That contradiction led me down a rabbit hole of metadata delays, missing commands, and hidden costs. Here's what I discovered.
The AI industry has a security problem: data scientists aren't trained in security, ML engineers are working with black-box models, and security pros don't understand GenAI. Learn about the frameworks and tools bridging this gap—from Llama Guard to Databricks' safety features.

Why DELETE isn’t enough under GDPR, and how Time Travel can make sensitive data reappear unless VACUUM is used correctly.

This blog shares my personal journey into Snowflake Gen AI, from early confusion to hands-on clarity. It offers practical study tips, common pitfalls, and guidance to help you prepare effectively and understand Snowflake’s evolving AI capabilities.

Started scrolling Instagram at 2 AM. Saw Cloudflare memes. Fell down a 4-hour research rabbit hole. Discovered that AND database = 'default' could have prevented the whole thing. My sleep schedule is ruined but at least I understand distributed systems now.

Discover the top 10 data pipeline tools every data engineer should know in 2025. From Airflow to Fivetran, learn how each tool powers modern data workflows, supports real-time analytics, and scales across cloud ecosystems.

Confused between a data lake, data warehouse, and data mart? Discover key differences, real-world use cases, and when to use each architecture. Learn how to build a modern, layered data strategy for scalability, governance, and business insights.

Explore what syntax means in the world of data and AI—from SQL and Python to JSON and APIs. Learn why syntax matters, common errors, real-world examples, and essential best practices for data engineers, analysts, and AI developers in 2025.

Discover how AWS Data Pipeline helps automate data movement and transformation across AWS services like S3, Redshift, and EMR. Learn its key features, benefits, limitations, and how it compares to modern tools like AWS Glue and MWAA.

Learn how to build scalable and secure data pipeline architectures in 2024 with best practices, modern tools, and intelligent design. Explore key pillars like scalability, security, observability, and metadata tracking to create efficient and future-proof data workflows.

Explore the key differences between ETL and ELT data integration methods in this comprehensive guide. Learn when to choose each approach, their use cases, and how to implement them for efficient data pipelines, real-time analytics, and scalable solutions.
Learn the essential role of ETL (Extract, Transform, Load) in data engineering. Understand the three phases of ETL, its benefits, and how to implement effective ETL pipelines using modern tools and strategies for better decision-making, scalability, and data quality.

Discover why data orchestration and analysis are essential for modern data systems. Learn how automation tools streamline data workflows, boost insights, and scale with your business
Learn what a data ingestion pipeline is, why it's vital for modern analytics, and how to design scalable, real-time pipelines to power your data systems effectively.

Discover the top 15 data warehouse tools for scalable data management in 2024. Learn how to choose the right platform for analytics, performance, and cost-efficiency.

Confused between a data mart and a data warehouse? Learn the key differences, use cases, and how to choose the right data architecture for your business. Explore best practices, real-world examples, and expert insights from Enqurious.

Discover the top 10 predictive analytics tools to know in 2025—from SAS and Google Vertex AI to RapidMiner and H2O.ai. Learn why predictive analytics is essential for modern businesses and how to choose the right tool for your data strategy.

Explore the key differences between descriptive and predictive analytics, and learn how both can drive smarter decision-making. Discover how these analytics complement each other to enhance business strategies and improve outcomes in 2025 and beyond.

Explore the key differences between predictive and prescriptive analytics, and learn how both can drive smarter decisions, enhance agility, and improve business outcomes. Discover real-world applications and why mastering both analytics approaches is essential for success in 2025 and beyond.

Compare PostgreSQL vs SQL Server in this comprehensive guide. Learn the key differences, strengths, and use cases to help you choose the right database for your business needs, from cost to performance and security.

Learn what Power BI is and how it works in this beginner's guide. Discover its key features, components, benefits, and real-world applications, and how it empowers businesses to make data-driven decisions.

Explore what a Business Intelligence Engineer does—from building data pipelines to crafting dashboards. Learn key responsibilities, tools, and why this role is vital in a data-driven organization.

Discover why data lineage is essential in today’s complex data ecosystems. Learn how it boosts trust, compliance, and decision-making — and how Enqurious helps you trace, govern, and optimize your data journeys.

Learn what a data mart is, its types, and key benefits. Discover how data marts empower departments with faster, targeted data access for improved decision-making, and how they differ from data warehouses and data lakes.

Master data strategy: Understand data mart vs data warehouse key differences, benefits, and use cases in business intelligence. Enqurious boosts your Data+AI team's potential with data-driven upskilling.

Learn what Azure Data Factory (ADF) is, how it works, and why it’s essential for modern data integration, AI, and analytics. This complete guide covers ADF’s features, real-world use cases, and how it empowers businesses to streamline data pipelines. Start your journey with Azure Data Factory today!

Discover the key differences between SQL and MySQL in this comprehensive guide. Learn about their purpose, usage, compatibility, and how they work together to manage data. Start your journey with SQL and MySQL today with expert-led guidance from Enqurious!

Learn Power BI from scratch in 2025 with this step-by-step guide. Explore resources, tips, and common mistakes to avoid as you master data visualization, DAX, and dashboard creation. Start your learning journey today with Enqurious and gain hands-on training from experts!

AI tools like ChatGPT are transforming clinical data management by automating data entry, enabling natural language queries, detecting errors, and simplifying regulatory compliance. Learn how AI is enhancing efficiency, accuracy, and security in healthcare data handling.

Big Data refers to large, complex data sets generated at high speed from various sources. It plays a crucial role in business, healthcare, finance, education, and more, enabling better decision-making, predictive analytics, and innovation.

Discover the power of prompt engineering and how it enhances AI interactions. Learn the key principles, real-world use cases, and best practices for crafting effective prompts to get accurate, creative, and tailored results from AI tools like ChatGPT, Google Gemini, and Claude.

Learn what a Logical Data Model (LDM) is, its key components, and why it’s essential for effective database design. Explore how an LDM helps businesses align data needs with IT implementation, reducing errors and improving scalability.

Discover the power of a Canonical Data Model (CDM) for businesses facing complex data integration challenges. Learn how CDM simplifies communication between systems, improves data consistency, reduces development costs, and enhances scalability for better decision-making.

Discover the 10 essential benefits of Engineering Data Management (EDM) and how it helps businesses streamline workflows, improve collaboration, ensure security, and make smarter decisions with technical data.

Explore how vibe coding is transforming programming by blending creativity, collaboration, and technology to create a more enjoyable, productive, and human-centered coding experience.

Learn how Azure Databricks empowers data engineers to build optimized, scalable, and reliable data pipelines with features like Delta Lake, auto-scaling, automation, and seamless collaboration.

Explore the top 10 data science trends to watch out for in 2025. From generative AI to automated machine learning, discover how these advancements are shaping the future of data science and transforming industries worldwide.

Discover the key differences between data scientists and data engineers, their roles, responsibilities, and tools. Learn how Enqurious helps you build skills in both fields with hands-on, industry-relevant learning.

Discover the 9 essential steps to effective engineering data management. Learn how to streamline workflows, improve collaboration, and ensure data integrity across engineering teams.

Azure Databricks is a cloud-based data analytics platform that combines the power of Apache Spark with the scalability, security, and ease of use offered by Microsoft Azure. It provides a unified workspace where data engineers, data scientists, analysts, and business users can collaborate.

In today's data-driven world, knowing how to make sense of information is a crucial skill. We’re surrounded by test scores, app usage stats, survey responses, and sales figures — and all this raw data on its own isn’t helpful.

In this blog, we will discuss some of the fundamental differences between AI inference vs. training—one that is, by design, artificially intelligent.

This guide provides a clear, actionable roadmap to help you avoid common pitfalls and successfully earn your SnowPro Core Certification, whether you’re making a career pivot or leveling up in your current role.

"Ever had one of those days when you’re standing in line at a store, waiting for a sales assistant to help you find a product?" In this blog we will get to know about -What is RAG, different types of RAG Architectures and pros and cons for each RAG.

Discover how Databricks and Snowflake together empower businesses by uniting big data, AI, and analytics excellence

How do major retailers like Walmart handle thousands of customer queries in real time without breaking a sweat? From answering questions instantly to providing personalized shopping recommendations, conversational AI reshapes how retailers interact with their customers.